Скрупулезный xmlrpc php. Введение в XML-RPC
Технология XML-RPC применяется в системе WordPress для разных приятных фишек по типу пингбэков, трекбеков, удаленного управления сайтом без входа в админку и т.п. К сожалению, злоумышленники могут использовать ее для DDoS атаки на сайты. То есть вы создаете красивые интересные WP проекты для себя или на заказ и при этом, ничего не подозревая, можете быть частью ботнета для DDoS`а. Соединяя воедино десятки и сотни тысяч площадок, нехорошие люди создают мощнейшую атаку на свою жертву. Хотя при этом ваш сайт также страдает, т.к. нагрузка идет на хостинг, где он размещен.
Свидетельством такой нехорошей активности могут быть логи сервера (access.log в nginx), содержащие следующие строки:
103.238.80.27 - - «POST /wp-login.php HTTP/1.0» 200 5791 "-" "-"
Но вернемся к уязвимости XML-RPC. Визуально она проявляется в медленном открытии сайтов на вашем сервере или же невозможностью их загрузки вообще (502 ошибка Bad Gateway). В тех.поддержке моего хостера FASTVPS подтвердили догадки и посоветовали:
- Обновить WordPress до последней версии вместе с плагинами. Вообще, если вы следите за , то могли читать о необходимости установки последней 4.2.3. из-за критических замечаний в безопасности (точно также как предыдущих версий). Короче говоря, обновляться полезно.
- Установить плагин Disable XML-RPC Pingback.
Отключение XML-RPC в WordPress
Раньше, как мне кажется, опция включения/отключения XML-RPC была где-то в настройках системы, однако сейчас не могу ее там найти. Поэтому самый простой метод избавиться от нее — использовать соответствующий плагин.

Найти и скачать Disable XML-RPC Pingback либо установив его непосредственно из админки системы. Вам не нужно ничего дополнительно настраивать, модуль сразу же начинает работать. Он удаляет методы pingback.ping и pingback.extensions.getPingbacks из XML-RPC интерфейса. Кроме того, удаляет X-Pingback из HTTP заголовков.
В одном из блогов нашел еще парочку вариантов удаления отключения XML-RPC.
1. Отключение XML-RPC в шаблоне.
Для этого в файл функций темы functions.php добавляется строка:
Последние два метода лично я не использовал, т.к. подключил плагин Disable XML-RPC Pingback — думаю, его будет достаточно. Просто для тех, кто не любит лишние установки, предложил альтернативные варианты.
Использование XML-RPC в PHP для публикации материалов в LiveJournal.com (ЖЖ)
Для начала вам потребуется скачать библиотеку XML-RPC. Наиболее удачной версией мне кажется свободно распространяемая через sourceforge " ": Все примеры ниже будут приведены для этой библиотеки версии 2.2.
Что же такое XML-RPC? RPC расшифровывается как Remote Procedure Call, соответственно на русский это можно перевести как удаленный вызов процедур с помощью XML. Сама методика удаленного вызова процедуры известна давно и используется в таких технологиях, как DCOM, SOAP, CORBA. RPC предназначен для построения распределенных клиент-серверных приложений. Это дает возможность строить приложения, которые работают в гетерогенных сетях, например, на компьютерах различных систем, производить удаленную обработку данных и управление удаленными приложениями. В частности этим протоколом пользуется хорошо известный в России сайт livejournal.com.
Рассмотрим пример, как можно разместить кириллическую запись (а именно с этим часто возникают
проблемы) в ЖЖ. Ниже приведен работающий код с комментариями:
new xmlrpcval($name, "string"), "password" => new xmlrpcval($password, "string"), "event" => new xmlrpcval($text, "string"), "subject" => new xmlrpcval($subj, "string"), "lineendings" => new xmlrpcval("unix", "string"), "year" => new xmlrpcval($year, "int"), "mon" => new xmlrpcval($mon, "int"), "day" => new xmlrpcval($day, "int"), "hour" => new xmlrpcval($hour, "int"), "min" => new xmlrpcval($min, "int"), "ver" => new xmlrpcval(2, "int")); /* на основе массива создаем структуру */ $post2 = array(new xmlrpcval($post, "struct")); /* создаем XML сообщение для сервера */ $f = new xmlrpcmsg("LJ.XMLRPC.postevent", $post2); /* описываем сервер */ $c = new xmlrpc_client("/interface/xmlrpc", "www.livejournal.com", 80); $c->request_charset_encoding = "UTF-8"; /* по желанию смотрим на XML-код того что отправится на сервер */ echo nl2br(htmlentities($f->serialize())); /* отправляем XML сообщение на сервер */ $r = $c->send($f); /* анализируем результат */ if(!$r->faultCode()) { /* сообщение принято успешно и вернулся XML-результат */ $v = php_xmlrpc_decode($r->value()); print_r($v); } else { /* сервер вернул ошибку */ print "An error occurred: "; print "Code: ".htmlspecialchars($r->faultCode()); print "Reason: "".htmlspecialchars($r->faultString()).""\n"; } ?>
В данном примере рассмотрен только один метод LJ.XMLRPC.postevent - полный список возможных команд и их синтаксис (на английском языке) доступен по адресу:
Организация обработки потока с эффективным использованием памяти
Эллиотт Хэролд (Elliot Rusty Harold)
Опубликовано 11.10.2007
PHP 5 представил XMLReader , новый класс для чтения расширяемого языка разметки (XML). В отличие от простого XML или объектной модели документов (DOM) XMLReader работает в потоковом режиме. То есть он считывает документ от начала до конца. Можно начать работать с содержимым документа в его начале, перед тем как вы увидите его окончание. Это делает работу очень быстрой, эффективной и очень экономной с точки зрения затрат памяти. Чем больше размер документов, которые необходимо обрабатывать, тем это важнее.
libxml
Описываемый XMLReader API основывается на libxml-библиотеке Gnome Project для C и C++. На самом деле XMLReader - это всего лишь тонкий PHP-слой на поверхности API libxml XmlTextReader . XmlTextReader также смоделирован на основе (хотя и не имеет общего кода) .NET классов XmlTextReader и XmlReader .
В отличие от простого API для XML (SAX), XMLReader - в большей мере принимающий парсер (pull parser), чем передающий парсер (push parser). Это означает, что программа находится под контролем. Вместо того, чтобы парсер сообщал вам, что он видит, когда он это видит; вы указываете парсеру, когда необходимо переходить к следующему фрагменту документа. Вы запрашиваете контент вместо того, чтобы реагировать на него. Другими словами, это можно представить так XMLReader - это реализация конструктивного шаблона Iterator (итератор), а не конструктивного шаблона Observer (наблюдатель).
Образец задачи
Давайте начнем с простого примера. Представьте, что вы пишете PHP-скрипт, который получает XML-RPC запросы и генерирует ответы. Точнее, представьте, что запросы выглядят, как показано в листинге 1. Корневой элемент документа methodCall , в котором содержатся элементы methodName и params . Название метода - sqrt . Элемент params содержит один элемент param , включающий в себя double - число, квадратный корень которого нужно извлечь. Области имен не используются.
Листинг 1. Запрос XML-RPC
Вот что должен делать PHP-скрипт:
- Проверить название метода и сгенерировать сигнал о сбое (fault response), если это не sqrt (единственный метод, который может быть обработан этим сценарием).
- Найти аргумент и, если он отсутствует или имеет неправильный тип, сгенерировать сигнал о сбое.
- В противном случае вычислить квадратный корень.
- Вернуть результат в форме, показанной в листинге 2.
Листинг 2. Ответ XML-RPC
Давайте рассмотрим это шаг за шагом.
Инициализация парсера и загрузка документа
Первым шагом является создание нового объекта парсера. Сделать это просто:
$reader = new XMLReader();Добавление информации к исходным отправляемым данным
Если вы обнаружите, что $HTTP_RAW_POST_DATA пуст, добавьте следующую строку в файл php.ini:
always_populate_raw_post_data = On
$request = $HTTP_RAW_POST_DATA; $reader->XML($request);Можно проанализировать любую строку, откуда бы вы ее ни взяли. Например, это может быть строковая литеральная константа в программе или содержимое файла. Также можно загрузить данные с внешнего URL при помощи функции open() . К примеру, следующая инструкция готовит один из Atom-каналов для разбора:
$reader->XML("http://www.cafeaulait.org/today.atom");Откуда бы вы ни взяли исходные данные, программа чтения теперь установлена и готова выполнять анализ.
Чтение документа
Функция read() перемещает парсер к следующему маркеру. Самый простой подход заключается в выполнении итераций цикла while по всему документу:
while ($reader->read()) { // обрабатывающий код... }По окончании закройте парсер, чтобы освободить ресурсы, которые он занимает, и перенастройте его для следующего документа:
$reader->close();Внутри цикла парсер помещается в определенном узле: в начале элемента, в конце элемента, в текстовом узле, в комментарии и так далее. Следующие свойства позволяют узнать, что парсер просматривает в данный момент:
- localName - это локальное, предварительно не заданное имя узла.
- name - возможное предварительно заданное имя узла. Для таких узлов, которые не имеют имен, например, комментариев, это #comment , #text , #document , и т. д., как в DOM (объектная модель документов).
- namespaceURI - это унифицированный идентификатор ресурса (URI) для пространства имен узла.
- nodeType - это целое число, представляющее тип узла - к примеру, 2 для узла атрибута и 7 - для оператора обработки.
- prefix - это префикс пространства имен узла.
- value - это текстовое содержание узла.
- hasValue - верно, если узел имеет текстовое значение и неверно в противном случае.
Конечно, не все типы узлов обладают всеми этими свойствами. Например, текстовые узлы, CDATA-разделы, комментарии, операторы обработки, атрибуты, символ пробела, типы документов и описания XML имеют значения. Другие типы узлов (в особенности – элементы и документы) – не имеют. Обычно программа использует свойство nodeType для определения того, что просматривается, и выдачи соответствующего ответа. В листинге 3 показан простой цикл while , который использует эти функции для вывода того, что он просматривает. В листинге 4 показан результат работы этой программы, когда ей на вход подается листинг 1.
Листинг 3. Что видит парсер
while ($reader->read()) { echo $reader->name; if ($reader->hasValue) { echo ": " . $reader->value; } echo "\n"; }Листинг 4. Вывод из листинга 3
methodCall #text: methodName #text: sqrt methodName #text: params #text: param #text: value double #text: 10 double value #text: param #text: params #text: methodCallБольшая часть программ не так универсальна. Они принимают входные данные в особой форме и обрабатывают их определенным образом. В примере XML-RPC нужно считать только один параметр из входных данных: элемент double , который должен быть только один. Чтобы это сделать, найдите начало элемента с именем double:
if ($reader->name == "double" && $reader->nodeelementType == XMLReader::element) { // ... }У этого элемента также есть единственный текстовый дочерний узел, который можно считывать, перемещая парсер к следующему узлу:
if ($reader->name == "double" && $reader->nodeType == XMLReader::ELEMENT) { $reader->read(); respond($reader->value); }Здесь функция respond() создает ответ XML-RPC и отправляет его клиенту. Однако, прежде чем я покажу это, необходимо рассказать еще кое-что. Нет никакой гарантии того, что элемент double в документе запроса содержит только один текстовый узел. Он может содержать несколько узлов, а также комментарии и операторы. Например, это может выглядеть следующим образом:
Вложенные элементы
В данной схеме есть один возможный дефект. Вложенные элементы double , например,
Устойчивое решение проблемы должно обеспечивать получение всех потомков текстового узла double , объединять их в цепочку и только затем конвертировать результат в double . Необходимо избегать любых комментариев или других возможных нетекстовых узлов. Это немного сложнее, но, как показано в листинге 5, не слишком.
Листинг 5. Суммируйте весь текстовый контент элемента
while ($reader->read()) { if ($reader->nodeType == XMLReader::TEXT || $reader->nodeType == XMLReader::CDATA || $reader->nodeType == XMLReader::WHITESPACE || $reader->nodeType == XMLReader::SIGNIFICANT_WHITESPACE) { $input .= $reader->value; } else if ($reader->nodeType == XMLReader::END_ELEMENT && $reader->name == "double") { break; } }Пока весь остальной контент документа можно игнорировать. (Позже я продолжу описание обработки ошибок).
Создание ответа
Как следует из имени, XMLReader предназначен только для чтения. Соответствующий класс XMLWriter сейчас находится в разработке, но еще не готов. К счастью, писать XML гораздо легче, чем его считывать. Во-первых, следует задать тип носителя ответа, используя функцию header() . Для XML-RPC это application/xml . Например:
header("Content-type: application/xml");Листинг 6. Отображение XML
function respond($input) { echo "Можно даже вставить буквенные части ответа прямо в страницу PHP, так же, как это было бы реализовано в HTML. Данная технология показана в листинге 7.
Листинг 7. Буквенный XML
function respond($input) { ?>Обработка ошибок
До настоящего момента подразумевалось, что входной документ оформлен корректно. Однако этого никто не может гарантировать. Как любой парсер XML, XMLReader должен прекратить обработку, как только обнаружит ошибку оформления. Если это происходит, то функция read() возвращает false (ложь).
Теоретически, парсер может обрабатывать данные до первой обнаруженной им ошибки. В моих экспериментах с маленькими документами, однако, он сталкивается с ошибкой почти сразу. Лежащий в основе парсер предварительно анализирует большой участок документа, кэширует его, а затем выдает его по частям. Таким образом, он обычно определяет ошибки на предварительном этапе. В целях безопасности лучше не берите на себя ответственность за то, что сможете выполнить анализ контента до первой ошибки оформления. Более того, не предполагайте, что не увидите никакого контента до ошибки парсера. Если нужно принять только полные, корректно оформленные документы, то убедитесь, что скрипт не делает ничего необратимого до самого конца документа.
Если парсер обнаруживает ошибку в оформлении, то функция read() отображает сообщение об ошибке, аналогичное представленному (если настроен подробный отчет об ошибке, как и должно быть на сервере разработки):
Warning: XMLReader::read() [function.read]: < value>
Вы, возможно, не захотите копировать отчет на страницу HTML, представляемую пользователю. Лучше фиксировать сообщение об ошибке в переменной среды $php_errormsg . Для этого нужно включить опцию конфигурации track_errors в файле php.ini:
track_errors = OnПо умолчанию опция track_errors отключена, что явно указано в php.ini, поэтому не забудьте изменить эту строку. Если вы добавите строку, показанную выше, в начало php.ini, то строка track_errors = Off , которая написана ниже, заменит ее.
Эта программа должна посылать ответы только на полные, правильно оформленные входные данные. (Также достоверные, но об этом позже.) Таким образом, нужно подождать завершения анализа документа (выход из цикла while). Теперь проверьте, изменилось ли значение $php_errormsg . Если нет, то документ оформлен корректно, и будет отправлено ответное сообщение XML-RPC. Если переменная задана, то это означает, что документ оформлен некорректно, и будет отправлен сигнал о сбое XML-RPC. Также сигнал о сбое отправляется, если запрашивается квадратный корень отрицательного числа. Смотрите листинг 8.
Листинг 8. Проверка корректного оформления
// отправка запроса (request) $request = $HTTP_RAW_POST_DATA; error_reporting(E_ERROR | E_WARNING | E_PARSE); if (isset($php_errormsg)) unset(($php_errormsg); // создание программы считывания (reader) $reader = new XMLReader(); // $reader->setRelaxNGсхемой("request.rng"); $reader->XML($request); $input = ""; while ($reader->read()) { if ($reader->name == "double" && $reader->nodeType == XMLReader::ELEMENT) { while ($reader->read()) { if ($reader->nodeType == XMLReader::TEXT || $reader->nodeType == XMLReader::CDATA || $reader->nodeType == XMLReader::WHITESPACE || $reader->nodeType == XMLReader::SIGNIFICANT_WHITESPACE) { $input .= $reader->value; } else if ($reader->nodeType == XMLReader::END_ELEMENT && $reader->name == "double") { break; } } break; } } // проверка корректного оформления входной информации if (isset($php_errormsg)) fault(21, $php_errormsg); else if ($input < 0) fault(20, "Cannot take square root of negative number"); else respond($input);Здесь приведена упрощенная версия общего шаблона обработки потоков XML. Парсер заполняет структуру данных, в соответствии с которой выполняются действия, когда документ заканчивается. Обычно структура данных проще, чем сам документ. Здесь структура данных особенно простая: единственная строка.
Валидация
Версия libxml
В ранних версиях libxml , библиотеки, от которой зависит XMLReader , присутствовали серьезные недочеты RELAX NG. Убедитесь, что вы используете хотя бы версию 2.06.26. Многие системы, в том числе Mac OS X Tiger, содержат более ранний выпуск с недочетами.
До сих пор я не придавал большого значения проверке того, действительно ли данные находятся там, где я думаю. Самый простой способ осуществить эту проверку – сравнить документ со схемой. XMLReader поддерживает язык описания схемы RELAX NG; в листинге 9 показана простая схема RELAX NG для данной конкретной формы запроса XML-RPC.
Листинг 9. Запрос XML-RPC
Схему можно добавить непосредственно в PHP-скрипт в виде строкового литерала при помощи setRelaxNGSchemaSource() или считать ее из внешнего файла или URL с помощью setRelaxNGSchema() . Например, при условии, что содержимое листинга 9 записано в файле sqrt.rng, схема будет загружаться следующим образом:
reader->setRelaxNGSchema("sqrt.rng")Выполните это прежде , чем начнете анализировать документ. Парсер сравнивает документ со схемой во время чтения. Чтобы проверить, является ли документ достоверным, вызовите функцию isValid() , которая возвращает значение true, если документ валиден (на данном этапе) и false в противном случае. В листинге 10 показана полная логически завершенная программа, содержащая обработку всех ошибок. Программа должна принимать любые достоверные входные данные и возвращать правильные значения и отклонять все неправильные запросы. Я также добавил метод fault() , который отправляет сигнал о сбое XML-RPC, если что-то идет не так.
Листинг 10. Полная серверная часть извлечения квадратного корня XML-RPC
Атрибуты
Атрибуты не видны при нормальном выполнении анализа. Чтобы считать атрибуты, необходимо остановиться в начале элемента и запросить конкретный атрибут либо по имени, либо по номеру.
Передайте имя атрибута, значение которого необходимо найти в текущем элементе, функции getAttribute() . К примеру, следующая конструкция запрашивает атрибут id текущего элемента:
$id = $reader->getAttribute("id");Если атрибут - в пространстве имен, например, xlink:href , то вызовите getAttributeNS () и передайте локальное имя и URI пространства имен в качестве первого и второго аргументов соответственно (префикс не имеет значения). Например, данная инструкция запрашивает значение атрибута xlink:href в пространстве имен http://www.w3.org/1999/xlink/:
$href = $reader->getAttributeNS ("href", "http://www.w3.org/1999/xlink/");Если атрибут не существует, то оба метода возвратят пустую строку. (Это неправильно, так как они должны вернуть null. Данная реализация усложняет возможность различать атрибуты, значение которых - пустая строка, и те, которые вообще отсутствуют.)
Порядок атрибутов
В XML-документах порядок атрибутов не имеет значения и не сохраняется парсером. Он использует номера для индексирования атрибутов просто ради удобства. Нет гарантии, что первый атрибут в открывающем теге будет атрибутом 1, второй будет атрибутом 2 и т.д. Не создавайте код, зависящий от порядка атрибутов.
Если нужно знать все атрибуты элемента, а их имена заранее неизвестны, то вызовите moveToNextAttribute() , когда считывающая часть установлена на элементе. Если парсер находится на узле атрибута, то можно считать его имя, пространство имен и значение при помощи тех же свойств, которые использовались для элементов. Например, следующий фрагмент кода распечатывает все атрибуты текущего элемента:
if ($reader->hasAttributes and $reader->nodeType == XMLReader::ELEMENT) { while ($reader->moveToNextAttribute()) { echo $reader->name . "="" . $reader->value . ""\n"; } echo "\n"; }Очень необычно для XML API то, что XMLReader позволяет считывать атрибуты либо с начала, либо с конца элемента. Чтобы избежать двойного отсчета, важно убедиться, что типом узла является XMLReader::ELEMENT , а не XMLReader::END_ELEMENT , у которого тоже могут быть атрибуты.
Заключение
XMLReader - полезное дополнение к инструментарию программиста PHP. В отличие от SimpleXML это полный парсер XML, который обрабатывает все документы, а не только некоторые из них. В отличие от DOM он может обрабатывать документы большие, чем доступная память. В отличие от SAX он устанавливает контроль над программой. Если PHP-программам нужно принимать входные данные XML, то стоит всерьез задуматься об использовании XMLReader .
Несколько дней назад я заметил, что нагрузка моих сайтов на хостинг выросла в разы. Если обычно она составляла в районе 100-120 "попугаев" (CP), то за последние несколько дней она возросла до 400-500 CP. Ничего хорошего в этом нет, ведь хостер может перевести на более дорогой тариф, а то и вовсе прикрыть доступ к сайтам, поэтому я начал разбираться.
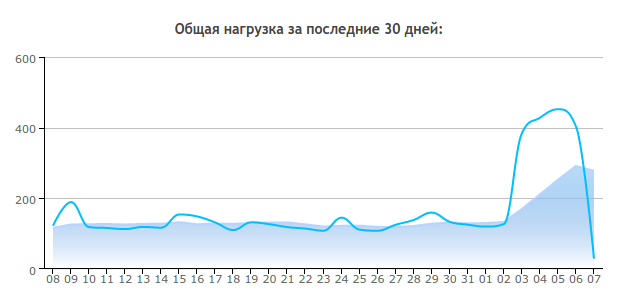
Но я выбрал метод, который позволит сохранить функциональность XML-RPC: установку плагина Disable XML-RPC Pingback . Он удаляет лишь "опасные" методы pingback.ping и pingback.extensions.getPingbacks, оставляя функционал XML-RPC. После установки плагин нужно всего лишь активировать - дальнейшая настройка не требуется.
Попутно я забил все IP атакующих в файл.htaccess своих сайтов, чтобы заблокировать им доступ. Просто дописал в конец файла:
Order Allow,Deny Allow from all Deny from 5.196.5.116 37.59.120.214 92.222.35.159
Вот и все, теперь мы надежно защитили блог от дальнейших атак с использованием xmlrpc.php. Наши сайты перестали грузить хостинг запросами, а также атаковать при помощи DDoS сторонние сайты.
Введение в XML-RPC
В Сети существует много разных ресурсов, которые предоставляют пользователям определенную информацию. Имеются в виду не обычные статические страницы, а, к примеру, данные, извлекаемые из базы данных или архивов. Это может быть архив финансовых данных (курсы валют, данные котировок ценных бумаг), данные о погоде, или же более объемная информация - новости, статьи, сообщения из форумов. Такая информация может представляться посетителю страницы, к примеру, через форму, как ответ на запрос, или же каждый раз генерироваться динамически. Но трудность в том, что часто такая информация нужна не столько конечному пользователю - человеку, сколько другим системам, программам, которые эти данные будут использовать для своих расчетов или других потребностей.
Реальный пример: страница банковского сайта, на которой показываются котировки валют. Если вы заходите на страницу как обычный пользователь, через браузер, вы видите все оформление страницы, баннеры, меню и другую информацию, которая "обрамляет" истинную цель поиска - котировки валют. Если вам надо вносить эти котировки в свой интернет-магазин, то ничего другого не останется, как только вручную выделить нужные данные и через буфер обмена перенести на свой сайт. И так придется делать каждый день. Неужели нет выхода?
Если решать проблему "в лоб", то сразу напрашивается решение: программа (скрипт на сайте), которой надо данные, получает страницу от сервера как "обычный пользователь", разбирает (парсит) полученный html-код и выделяет из него нужную информацию. Это можно сделать или обычным регулярным выражением, или при помощи любого html-парсера. Сложность подхода - в его неэфективности. Во-первых, для получения небольшой порции данных (данные о валютах - это буквально десяток-другой символов) надо получать всю страницу, а это не менее нескольких десятков килобайт. Во-вторых, при любом изменении кода страницы, к примеру, дизайн поменялся или что-то еще, наш алгоритм разбора придется переделывать. Да и ресурсов это будет отбирать порядочно.
Поэтому разработчики пришли к решению - надо разработать какой-то универсальный механизм, который бы позволил прозрачно (на уровне протокола и среды передачи) и легко обмениваться данными между программами, которые могут находиться где угодно, быть написанными на любом языке и работать под управлением любой операционной системы и на любой аппаратной платформе. Такой механизм называют сейчас громкими терминами "Веб-сервисы" (web-service), "SOAP", "архитектура, ориентированная на сервисы" (service-oriented architecture). Для обмена данными используются открытые и проверенные временем стандарты - для передачи сообщений протокол HTTP (хотя можно использовать и другие протоколы - SMTP к примеру). Сами данные (в нашем примере - курсы валют) передаются упакованными в кросс-платформенный формат - в виде XML-документов. Для этого придуман специальный стандарт - SOAP.
Да, сейчас веб-сервисы, SOAP и XML у всех на слуху, их начинают активно внедрять и крупные корпорации вроде IBM и Microsoft выпускают новые продукты, призванные помочь тотальному внедрению веб-сервисов.
Но! Для нашего примера с курсами валют, которые должны передаваться с сайта банка в движок интернет-магазина такое решение будет очень сложным. Ведь только описание стандарта SOAP занимает неприличные полторы тысячи страниц, и это еще не все. Для практического использования придется изучить еще работу со сторонними библиотеками и расширениями (только начиная с PHP 5.0 в него входит библиотека для работы с SOAP), написать сотни и тысячи строк своего кода. И все это для получения нескольких букв и цифр - явно очень тяжеловесно и нерационально.
Потому существует еще один, с натяжкой можно сказать альтернативный стандарт на обмен информацией - XML-RPC. Он был разработан при участии Microsoft компанией UserLand Software Inc и предназначен для унифицированной передачи данных между приложениями через Интернет. Он может заменить SOAP при построении простых сервисов, где не надо все "корпоративные" возможности настоящих веб-сервисов.
Что же означает аббревиатура XML-RPC? RPC расшифровывается как Remote Procedure Call - удаленный вызов процедур. Это значит, что приложение (неважно, скрипт на сервере или обычное приложение на клиентском компьютере) может прозрачно использовать метод, который физически реализован и исполняется на другом компьютере. XML тут применяется для обеспечения универсального формата описания передаваемых данных. Как транспорт, для передачи сообщений применяется протокол HTTP, что позволяет беспрепятственно обмениваться данными через любые сетевые устройства - маршрутизаторы, фаерволы, прокси-сервера.
И так, для использования надо иметь: сервер XML-RPC, который предоставляет один или несколько методов, клиент XML-RPC, который может формировать корректный запрос и обрабатывать ответ сервера, а также знать необходимые для успешной работы параметры сервера - адрес, название метода и передаваемые параметры.
Вся работа с XML-RPC происходит в режиме "запрос-ответ", в этом и есть одно из отличий технологии от стандарта SOAP, где есть и понятия транзакций, и возможность делать отложенные вызовы (когда сервер сохраняет запрос и отвечает на него в определенное время в будущем). Эти дополнительные возможности больше пригодятся для мощных корпоративных сервисов, они значительно усложняют разработку и поддержку серверов, и ставят дополнительные требования к разработчикам клиентских решений.
Процедура работы с XML-RPC начинается с формирования запроса. Типичный запрос выглядит так:
POST /RPC2 HTTP/1.0
User-Agent: eshop-test/1.1.1 (FreeBSD)
Host: server.localnet.com
Content-Type: text/xml
Content-length: 172
В первых строках формируется стандартный заголовок HTTP запроса POST. К обязательным параметрам относятся host, тип данных (MIME-тип), который должен быть text/xml, а также длина сообщения. Также в стандарте указывается, что поле User-Agent должно быть заполнено, но может содержать произвольное значение.
Далее идет обычный заголовок XML-документа. Корневой элемент запроса -
Строка
Далее задаются передаваемые параметры. Для этого служит секция
После описания всех параметров следуют закрывающие теги. Запрос и ответ в XML-RPC это обычные документы XML, поэтому все теги обязательно должны быть закрыты. А вот одиночных тегов в XML-RPC нет, хотя в стандарте XML они присутствуют.
Tеперь разберем ответ сервера. Заголовок HTTP ответа обычный, если запрос успешно обработан, то сервер возвращает ответ HTTP/1.1 200 OK. Также как в запросе, следует корректно указать MIME-тип, длину сообщения и дату формирования ответа.
Само тело ответа следующее:
Теперь вместо корневого тега
Если при обработке вашего запроса произошла ошибка, то вместо В
ответе будет элемент
А теперь рассмотрим кратко типы данных в XML-RPC. Всего типов данных есть 9 - семь простых типов и 2 сложных. Каждый тип описывается своим тегом или набором тегов (для сложных типов).
Простые типы:
Целые числа
- тег
Логический тип
- тег
ASCII-строка
- описывается тегом
Числа с плавающей точкой
- тег
Дата и время
- описывается тегом
Последним простым типом является строка, закодированная в base64
,
которая описывается тегом
Сложные типы представлены структурами и массивами. Структура определяется
корневым элементом
Массивы не имеют названий и описываются тегом
Конечно, кто-то скажет, что такой перечень типов данных очень беден и "не позволяет развернуться". Да, если надо передавать сложные объекты, или большие объемы данных, то лучше использовать SOAP. А для небольших, нетребовательных приложений вполне подходит и XML-RPC, более того, очень часто даже его возможностей оказывается слишком много! Если учесть легкость развертывания, очень большое количество библиотек для почти любых языков и платформ, широкую поддержку в PHP, то XML-RPC часто просто не имеет конкурентов. Хотя сразу советовать его в качестве универсального решения нельзя - в каждом конкретном случае надо решать по обстоятельствах.
-
 17 апреля 2015Оригинальный и альтернативный интерфейс: прошивать или нет?
17 апреля 2015Оригинальный и альтернативный интерфейс: прошивать или нет? -
 17 апреля 2015Motorola Moto X Force - подробный обзор характеристик
17 апреля 2015Motorola Moto X Force - подробный обзор характеристик -
 17 апреля 2015Что делать если украли iphone
17 апреля 2015Что делать если украли iphone

.jpg "Из цифры в ноты: лучший портативный ЦАП Большое в малом")




