OLAP в финансовом управлении. Технология OLAP Применение olap
С концепцией многомерного анализа данных тесно связывают оперативный анализ, который выполняется средствами OLAP-систем.
OLAP (On-Line Analytical Processing) -- технология оперативной аналитической обработки данных, использующая методы и средства для сбора, хранения и анализа многомерных данных в целях поддержки процессов принятия решений.
Основное назначение OLAP-систем -- поддержка аналитической деятельности, произвольных (часто используется термин ad-hoc) запросов пользователей-аналитиков. Цель OLAP-анализа -- проверка возникающих гипотез.
У истоков технологии OLAP стоит основоположник реляционного подхода Э. Кодд. В 1993 г. он опубликовал статью под названием «OLAP для пользователей-аналитиков: каким он должен быть». В данной работе изложены основные концепции оперативной аналитической обработки и определены следующие 12 требований, которым должны удовлетворять продукты, позволяющие выполнять оперативную аналитическую обработку. Токмаков Г.П. Базы данных. Концепция баз данных, реляционная модель данных, языки SQL. С. 51
Ниже перечислены 12 правил, изложенных Коддом и определяющих OLAP.
1. Многомерность -- OLAP-система на концептуальном уровне должна представлять данные в виде многомерной модели, что упрощает процессы анализа и восприятия информации.
2. Прозрачность -- OLAP-система должна скрывать от пользователя реальную реализацию многомерной модели, способ организации, источники, средства обработки и хранения.
3. Доступность -- OLAP-система должна предоставлять пользователю единую, согласованную и целостную модель данных, обеспечивая доступ к данным независимо оттого, как и где они хранятся.
4. Постоянная производительность при разработке отчетов -- производительность OLAP-систем не должна значительно уменьшаться при увеличении количества измерений, по которым выполняется анализ.
5. Клиент-серверная архитектура -- OLAP-система должна быть способна работать в среде «клиент-сервер», т.к. большинство данных, которые сегодня требуется подвергать оперативной аналитической обработке, хранятся распределенно. Главной идеей здесь является то, что серверный компонент инструмента OLAP должен быть достаточно интеллектуальным и позволять строить общую концептуальную схему на основе обобщения и консолидации различных логических и физических схем корпоративных БД для обеспечения эффекта прозрачности.
6. Равноправие измерений -- OLAP-система должна поддерживать многомерную модель, в которой все измерения равноправны. При необходимости дополнительные характеристики могут быть предоставлены отдельным измерениям, но такая возможность должна быть предоставлена любому измерению.
7. Динамическое управление разреженными матрицами -- OLAP-система должна обеспечивать оптимальную обработку разреженных матриц. Скорость доступа должна сохраняться вне зависимости от расположения ячеек данных и быть постоянной величиной для моделей, имеющих разное число измерений и различную степень разреженности данных.
8. Поддержка многопользовательского режима -- OLAP-система должна предоставлять возможность работать нескольким пользователям совместно с одной аналитической моделью или создавать для них различные модели из единых данных. При этом возможны как чтение, так и запись данных, поэтому система должна обеспечивать их целостность и безопасность.
9. Неограниченные перекрестные операции -- OLAP-система должна обеспечивать сохранение функциональных отношений, описанных с помощью определенного формального языка между ячейками гиперкуба при выполнении любых операций среза, вращения, консолидации или детализации. Система должна самостоятельно (автоматически) выполнять преобразование установленных отношений, не требуя от пользователя их переопределения.
10. Интуитивная манипуляция данными -- OLAP-система должна предоставлять способ выполнения операций среза, вращения, консолидации и детализации над гиперкубом без необходимости пользователю совершать множество действий с интерфейсом. Измерения, определенные в аналитической модели, должны содержать всю необходимую информацию для выполнения вышеуказанных операций.
11. Гибкие возможности получения отчетов -- OLAP-система должна поддерживать различные способы визуализации данных, т.е. отчеты должны представляться в любой возможной ориентации. Средства формирования отчетов должны представлять синтезируемые данные или информацию, следующую из модели данных в ее любой возможной ориентации. Это означает, что строки, столбцы или страницы должны показывать одновременно от 0 до N измерений, где N-- число измерений всей аналитической модели. Кроме того, каждое измерение содержимого, показанное в одной записи, колонке или странице, должно позволять показывать любое подмножество элементов (значений), содержащихся в измерении, в любом порядке.
12. Неограниченная размерность и число уровней агрегации -- исследование о возможном числе необходимых измерений, требующихся в аналитической модели, показало, что одновременно может использоваться до 19 измерений. Отсюда вытекает настоятельная рекомендация, чтобы аналитический инструмент мог одновременно предоставить хотя бы 15, а предпочтительно -- 20 измерений. Более того, каждое из общих измерений не должно быть ограничено по числу определяемых пользователем-аналитиком уровней агрегации и путей консолидации.
Дополнительные правила Кодда.
Набор этих требований, послуживших де-факто определением OLAP, достаточно часто вызывает различные нарекания, например, правила 1, 2, 3, 6 являются требованиями, а правила 10, 11 -- неформализованными пожеланиями. Токмаков Г.П. Базы данных. Концепция баз данных, реляционная модель данных, языки SQL. С. 68 Таким образом, перечисленные 12 требований Кодда не позволяют точно определить OLAP. В 1995 г. Кодд к приведенному перечню добавил следующие шесть правил:
13. Пакетное извлечение против интерпретации -- OLAP-система должна в равной степени эффективно обеспечивать доступ как к собственным, так и к внешним данным.
14. Поддержка всех моделей OLAP-анализа -- OLAP-система должна поддерживать все четыре модели анализа данных, определенные Коддом: категориальную, толковательную, умозрительную и стереотипную.
15. Обработка ненормализованных данных -- OLAP-система должна быть интегрирована с ненормализованными источниками данных. Модификации данных, выполненные в среде OLAP, не должны приводить к изменениям данных, хранимых в исходных внешних системах.
16. Сохранение результатов OLAP: хранение их отдельно от исходных данных -- OLAP-система, работающая в режиме чтения-записи, после модификации исходных данных должна результаты сохранять отдельно. Иными словами, обеспечивается безопасность исходных данных.
17. Исключение отсутствующих значений-- OLAP-система, представляя данные пользователю, должна отбрасывать все отсутствующие значения. Другими словами, отсутствующие значения должны отличаться от нулевых значений.
18. Обработка отсутствующих значений -- OLAP-система должна игнорировать все отсутствующие значения без учета их источника. Эта особенность связана с 17-м правилом.
Кроме того, Кодд разбил все 18 правил на следующие четыре группы, назвав их особенностями. Эти группы получили названия В, S, R и D.
Основные особенности (В) включают следующие правила:
Многомерное концептуальное представление данных (правило 1);
Интуитивное манипулирование данными (правило 10);
Доступность (правило 3);
Пакетное извлечение против интерпретации (правило 13);
Поддержка всех моделей OLAP-анализа (правило 14);
Архитектура «клиент-сервер» (правило 5);
Прозрачность (правило 2);
Многопользовательская поддержка (правило 8)
Специальные особенности (S):
Обработка ненормализованных данных (правило 15);
Сохранение результатов OLAP: хранение их отдельно от исходных данных (правило 16);
Исключение отсутствующих значений (правило 17);
Обработка отсутствующих значений (правило 18). Особенности представления отчетов (R):
Гибкость формирования отчетов (правило 11);
Стандартная производительность отчетов (правило 4);
Автоматическая настройка физического уровня (измененное оригинальное правило 7).
Управление измерениями (D):
Универсальность измерений (правило 6);
Неограниченное число измерений и уровней агрегации (правило 12);
Неограниченные операции между размерностями (правило 9).
Концепция технологии OLAP была сформулирована Эдгаром Коддом в 1993 г.
Эта технология основана на построении многомерных наборов данных - так называемых OLAP-кубов (не обязательно трехмерных, как можно было бы заключить из определения). Целью использования технологий OLAP является анализ данных и представление этого анализа в виде, удобном для восприятия управляющим персоналом и принятия на их основе решений.
Основные требования, предъявляемые к приложениям для многомерного анализа:
- - предоставление пользователю результатов анализа за приемлемое время (не более 5 с.);
- - многопользовательский доступ к данным;
- - многомерное представление данных;
- - возможность обращаться к любой информации независимо от места ее хранения и объема.
Инструменты OLAP-систем обеспечивают возможность сортировки и выборки данных по заданным условиям. Могут задаваться различные качественные и количественные условия.
Основной моделью данных, использованной в многочисленных инструментальных средствах создания и поддержки баз данных - СУБД, является реляционная модель. Данные в ней представлены в виде множества связанных ключевыми полями двумерных таблиц-отношений. Для устранения дублирования, противоречивости, уменьшения трудозатрат на ведение баз данных применяется формальный аппарат нормализации таблиц-сущностей. Однако применение его связано с дополнительными затратами времени на формирование ответов на запросы к базам данных, хотя и экономятся ресурсы памяти.
Многомерная модель данных представляет исследуемый объект в виде многомерного куба, чаще используют трехмерную модель. По осям или граням куба откладываются измерения или реквизиты-признаки. Реквизиты-основания являются наполнением ячеек куба. Многомерный куб может быть представлен комбинацией трехмерных кубов с целью облегчения восприятия и представления при формировании отчетных и аналитических документов и мультимедийных презентаций по материалам аналитических работ в системе поддержки принятия решений.
В рамках OLAP-технологий на основе того, что многомерное представление данных может быть организовано как средствами реляционных СУБД, так многомерных специализированных средств, различают три типа многомерных OLAP-систем:
- - многомерный (Multidimensional) OLAP-MOLAP;
- - реляционный (Relation) OLAP-ROLAP;
- - смешанный или гибридный (Hibrid) OLAP-HOLAP.
В многомерных СУБД данные организованы не в виде реляционных таблиц, а в виде упорядоченных многомерных массивов в виде гиперкубов, когда все хранимые данные должны иметь одинаковую размерность, что означает необходимость образовывать максимально полный базис измерений. Данные могут быть организованы в виде поликубов, в этом варианте значения каждого показателя хранятся с собственным набором измерений, обработка данных производится собственным инструментом системы. Структура хранилища в этом случае упрощается, т.к. отпадает необходимость в зоне хранения данных в многомерном или объектно-ориентированном виде. Снижаются огромные трудозатраты на создание моделей и систем преобразования данных из реляционной модели в объектную.
Достоинствами MOLAP являются:
- - более быстрое, чем при ROLAP получение ответов на запросы - затрачиваемое время на один-два порядка меньше;
- - из-за ограничений SQL затрудняется реализация многих встроенных функций.
К ограничениям MOLAP относятся:
- - сравнительно небольшие размеры баз данных;
- - за счет денормализации и предварительной агрегации многомерные массивы используют в 2,5-100 раз больше памяти, чем исходные данные (расход памяти при увеличении числа измерений растет по экспоненциальному закону);
- - отсутствуют стандарты на интерфейс и средства манипулирования данными;
- - имеются ограничения при загрузке данных.
Трудозатраты на создание многомерных данных резко увеличиваются, т.к. практически отсутствуют в этой ситуации специализированные средства объективизации реляционной модели данных, содержащихся в информационном хранилище. Время отклика на запросы часто не может уложиться в рамки требований к OLAP-системам.
Достоинствами ROLAP-систем являются:
- - возможность оперативного анализа непосредственно содержащихся в хранилище данных, т.к. большинство исходных баз данных - реляционного типа;
- - при переменной размерности задачи выигрывают RO- LAP, т.к. не требуется физическая реорганизация базы данных;
- - ROLAP-системы могут использовать менее мощные клиентские станции и серверы, причем на серверы ложится основная нагрузка по обработке сложных SQL-запросов;
- - уровень защиты информации и разграничения прав доступа в реляционных СУБД несравненно выше чем в многомерных.
Недостатком ROLAP-систем является меньшая производительность, необходимость тщательной проработки схем базы данных, специальная настройка индексов, анализ статистики запросов и учет выводов анализа при доработках схем баз данных, что приводит к значительным дополнительным трудозатратам.
Выполнение же этих условий позволяет при использовании ROLAP-систем добиться схожих с MOLAP-системами показателей в отношении времени доступа, а также превзойти в экономии памяти.
Гибридные OLAP-системы представляют собой сочетание инструментов, реализующих реляционную и многомерную модель данных. Это позволяет резко снизить затраты ресурсов на создание и поддержание такой модели, время отклика на запросы.
При таком подходе используются достоинства первых двух подходов и компенсируются их недостатки. В наиболее развитых программных продуктах такого назначения реализован именно этот принцип.
Использование гибридной архитектуры в OLAP-системах - это наиболее приемлемый путь решения проблем, связанных с применением программных инструментальных средств в многомерном анализе.
Режим выявления закономерностей основан на интеллектуальной обработке данных. Главной задачей здесь является выявление закономерностей в исследуемых процессах, взаимосвязей и взаимовлияния различных факторов, поиск крупных «непривычных» отклонений, прогноз хода различных существенных процессов. Эта область относится к интеллектуальному анализу (Data mining).
Механизм OLAP является на сегодня одним из популярных методов анализа данных. Есть два основных подхода к решению этой задачи. Первый из них называется Multidimensional OLAP (MOLAP) – реализация механизма при помощи многомерной базы данных на стороне сервера, а второй Relational OLAP (ROLAP) – построение кубов "на лету" на основе SQL запросов к реляционной СУБД. Каждый из этих подходов имеет свои плюсы и минусы. Их сравнительный анализ выходит за рамки этой статьи. Мы же опишем нашу реализацию ядра настольного ROLAP модуля.
Такая задача возникла после применения ROLAP системы, построенной на основе компонентов Decision Cube, входящих в состав Borland Delphi. К сожалению, использование этого набора компонент показало низкую производительность на больших объемах данных. Остроту этой проблемы можно снизить, стараясь отсечь как можно больше данных перед подачей их для построения кубов. Но этого не всегда бывает достаточно.
В Интернете и прессе можно найти много информации об OLAP системах, но практически нигде не сказано о том, как это устроено внутри. Поэтому решение большинства проблем нам давалось методом проб и ошибок.
Схема работы
Общую схему работы настольной OLAP системы можно представить следующим образом:
Алгоритм работы следующий:
- Получение данных в виде плоской таблицы или результата выполнения SQL запроса.
- Кэширование данных и преобразование их к многомерному кубу.
- Отображение построенного куба при помощи кросс-таблицы или диаграммы и т.п. В общем случае, к одному кубу может быть подключено произвольное количество отображений.
Рассмотрим как подобная система может быть устроена внутри. Начнем мы это с той стороны, которую можно посмотреть и пощупать, то есть с отображений.
Отображения, используемые в OLAP системах, чаще всего бывают двух видов – кросс-таблицы и диаграммы. Рассмотрим кросс-таблицу, которая является основным и наиболее распространенным способом отображения куба.
Кросс-таблица
На приведенном ниже рисунке, желтым цветом отображены строки и столбцы, содержащие агрегированные результаты, светло-серым цветом отмечены ячейки, в которые попадают факты и темно-серым ячейки, содержащие данные размерностей.

Таким образом, таблицу можно разделить на следующие элементы, с которыми мы и будем работать в дальнейшем:

Заполняя матрицу с фактами, мы должны действовать следующим образом:
- На основании данных об измерениях определить координаты добавляемого элемента в матрице.
- Определить координаты столбцов и строк итогов, на которые влияет добавляемый элемент.
- Добавить элемент в матрицу и соответствующие столбцы и строки итогов.
При этом нужно отметить то, что полученная матрица будет сильно разреженной, почему ее организация в виде двумерного массива (вариант, лежащий на поверхности) не только нерациональна, но, скорее всего, и невозможна в связи с большой размерностью этой матрицы, для хранения которой не хватит никакого объема оперативной памяти. Например, если наш куб содержит информацию о продажах за один год, и если в нем будет всего 3 измерения – Клиенты (250), Продукты (500) и Дата (365), то мы получим матрицу фактов следующих размеров:
Кол-во элементов = 250 х 500 х 365 = 45 625 000
И это при том, что заполненных элементов в матрице может быть всего несколько тысяч. Причем, чем больше количество измерений, тем более разреженной будет матрица.
Поэтому, для работы с этой матрицей нужно применить специальные механизмы работы с разреженными матрицами. Возможны различные варианты организации разреженной матрицы. Они довольно хорошо описаны в литературе по программированию, например, в первом томе классической книги "Искусство программирования" Дональда Кнута.
Рассмотрим теперь, как можно определить координаты факта, зная соответствующие ему измерения. Для этого рассмотрим подробнее структуру заголовка:
При этом можно легко найти способ определения номеров соответствующей ячейки и итогов, в которые она попадает. Здесь можно предложить несколько подходов. Один из них – это использование дерева для поиска соответствующих ячеек. Это дерево может быть построено при проходе по выборке. Кроме того, можно легко определить аналитическую рекуррентную формулу для вычисления требуемой координаты.
Подготовка данных
Данные, хранящиеся в таблице необходимо преобразовать для их использования. Так, в целях повышения производительности при построении гиперкуба, желательно находить уникальные элементы, хранящиеся в столбцах, являющихся измерениями куба. Кроме того, можно производить предварительное агрегирование фактов для записей, имеющих одинаковые значения размерностей. Как уже было сказано выше, для нас важны уникальные значения, имеющиеся в полях измерений. Тогда для их хранения можно предложить следующую структуру:

При использовании такой структуры мы значительно снижаем потребность в памяти. Что довольно актуально, т.к. для увеличения скорости работы желательно хранить данные в оперативной памяти. Кроме того, хранить можно только массив элементов, а их значения выгружать на диск, так как они будут нам требоваться только при выводе кросс-таблицы.
Библиотека компонентов CubeBase
Описанные выше идеи были положены в основу при создании библиотеки компонентов CubeBase.

TСubeSource осуществляет кэширование и преобразование данных во внутренний формат, а также предварительное агрегирование данных. Компонент TСubeEngine осуществляет вычисление гиперкуба и операции с ним. Фактически, он является OLAP-машиной, осуществляющей преобразование плоской таблицы в многомерный набор данных. Компонент TCubeGrid выполняет вывод на экран кросс-таблицы и управление отображением гиперкуба. TСubeChart позволяет увидеть гиперкуб в виде графиков, а компонент TСubePivote управляет работой ядра куба.
Сравнение производительности
Данный набор компонент показал намного более высокое быстродействие, чем Decision Cube. Так на наборе из 45 тыс. записей компоненты Decision Cube потребовали 8 мин. на построение сводной таблицы. CubeBase осуществил загрузку данных за 7сек. и построение сводной таблицы за 4 сек. При тестировании на 700 тыс. записей Decision Cube мы не дождались отклика в течение 30 минут, после чего сняли задачу. CubeBase осуществил загрузку данных за 45 сек. и построение куба за 15 сек.
На объемах данных в тысячи записей CubeBase отрабатывал в десятки раз быстрее Decision Cube. На таблицах в сотни тысяч записей – в сотни раз быстрее. А высокая производительность – один из самых важных показателей OLAP систем.
Цель доклада
В данном докладе речь пойдет об одной из категорий интеллектуальных технологий, которые являются удобным аналитическим инструментом – OLAP-технологиях.
Цель доклада: раскрыть и осветить 2 вопроса: 1) понятие OLAP и их прикладное значение в финансовом управлении; 2) реализация OLAP-функциональности в программных решениях: различия, возможности, преимущества, недостатки.
Сразу хочу отметить, что OLAP – это универсальный инструмент, который может быть использован в любой прикладной области, а не только в финансах (как это может быть понято из названия доклада), требующей анализа данных различными методами.
Управление финансами
Управление финансами – область, в которой как ни в какой другой важен анализ. Любое финансово-управленческое решение возникает как результат определенных аналитических процедур. Сегодня управление финансами приобретает важную роль для успешного функционирования предприятия. Не смотря на то, что финансовый менеджмент является вспомогательным процессом на предприятии, он требует особого внимания, так как ошибочные финансово-управленческие решения могут привести к большим потерям.
Управление финансами направлено на обеспечение предприятия финансовыми ресурсами в необходимых объемах, в нужное время и в нужном месте с целью получения максимального эффекта от их использования путем оптимального распределения.
Пожалуй, трудно определить уровень «максимальной эффективности использования ресурсов», но в любом случае,
Финансовый директор всегда должен знать:
- сколько финансовых ресурсов имеется?
- откуда будут поступать средства и в каких объемах?
- куда вкладывать более эффективно и почему?
- и в какие моменты времени все это необходимо совершать?
- сколько нужно для обеспечения нормальной деятельности предприятия?
Чтобы получать обоснованные ответы на эти вопросы необходимо иметь, анализировать и знать как анализировать достаточно большое количество показателей деятельности. Кроме того, ФУ охватывает огромное количество областей: анализ денежных потоков (движения денежных средств), анализ активов и пассивов, анализ прибыльности, маржинальный анализ, анализ рентабельности, ассортиментный анализ.
Знания
Поэтому ключевым фактором эффективности процесса управления финансами является наличие знаний:
- Личные знания в предметной области (можно сказать теоретико-методологические), включая опыт, интуицию финансиста/финансового директора
- Общие (корпоративные) знания или систематизированная информация о фактах свершения финансовых операций на предприятии (т. е. информация о прошлом, настоящем и будущем состоянии предприятия, представленная в различных показателях и измерениях)
Если первое лежит в области действий этого финансиста (или директора по персоналу, который нанимал этого работника), то второе должно целенаправленно создаваться на предприятии совместными усилиями работников финансовых и информационных служб.
Что есть сейчас
Однако сейчас на предприятиях типична парадоксальная ситуация: информация есть, ее очень много, слишком много. Но она пребывает в хаотическом состоянии: неструктурированна, несогласованна, разрознена, не всегда достоверна и часто ошибочна, ее практически невозможно найти и получить. Производится длительная и зачастую бесполезная генерация гор финансовой отчетности, которая неудобна для финансового анализа, трудна для восприятия, так как создается не для внутреннего управления, а для предоставления внешним контролирующим органам.
По результатам исследования, проведенного фирмой Reuters среди 1300 международных менеджеров, 38% опрошенных утверждают, что тратят много времени, пытаясь найти нужную информацию. Получается, что высококвалифицированный специалист тратит высокооплачиваемое время не на анализ данных, а на сбор, поиск и систематизацию необходимой для этого анализа информации. В то же время менеджеры испытывают тяжелую загрузку данными, часто не имеющими никакого отношения к делу, что опять таки снижает эффективность их работы. Причина такой ситуации: избыток информации и недостаток знаний.
Что надо делать
Информация должна превращаться в знания. Для современного бизнеса ценная информация, ее систематическое приобретение, синтез, обмен, использование – это своего рода валюта, но для того, чтобы ее получать, необходимо управлять информацией, как и любым бизнес-процессом.
Ключом к управлению информацией является доставка нужной информации в надлежащем виде заинтересованным лицам в пределах организации в конкретное время. Цель такого управления заключается в том, чтобы помочь людям лучше работать вместе, используя возрастающие объемы информации.
Информационные технологии в данном случае выступают средством, с помощью которого можно было бы систематизировать информацию на предприятии, предоставить определенным пользователям к ней доступ и дать им инструментальные средства для превращения этой информации в знания.
Базовые понятия OLAP-технологий
OLAP-технологии (от англ. On-Line Analytical Processing) – это название не конкретного продукта, а целой технологии оперативного анализа многомерных данных, накопленных в хранилище. Для того, чтобы понять сущность OLAP необходимо рассмотреть традиционный процесс получения информации для принятия решений.
Традиционная система поддержки принятия решений
Здесь, конечно, тоже может быть много вариантов: полный информационный хаос или же наиболее типичная ситуация, когда на предприятии существуют оперативные системы, с помощью которых регистрируются факты свершения определенных операций и их хранение в базах данных. Для извлечения данных из баз для аналитических целей построена система запросов определенных выборок данных.
Но такой способ поддержки принятия решений лишен гибкости и имеет много недостатков:
- используется ничтожно малое количество данных, которые могут быть полезны для принятия решений
- иногда создаются сложные многостраничные отчеты, из которых реально используются 1-2 строчки (остальное – на всякий случай) – информационная перегрузка
- медленная реакция процесса на изменения: если необходимо новое представление данных, то запрос должен быть формально описан и закодирован программистом, только затем выполнен. Время ожидания: часы, дни. А возможно решение необходимо сейчас, немедленно. А ведь после получения новой информации, возникнет новый вопрос (уточняющий)
Если отчеты по запросам представляются в одномерном формате – то проблемы бизнеса обычно многомерные и многогранные. Если требуется получить ясную картину бизнеса компании, то необходимо анализировать данные в различных разрезах.
Многие компании создают прекрасные реляционные базы данных, идеально разложив по полочкам горы неиспользуемой информации, которая сама по себе не обеспечивает ни быстрой, ни достаточно грамотной реакции на рыночные события. ДА - реляционные БД были, есть и будут наиболее подходящей технологией для хранения корпоративных данных. Речь идет не о новой технологии БД, а, скорее, об инструментальных средствах анализа, дополняющих функции существующих СУБД и достаточно гибких, чтобы предусмотреть и автоматизировать разные виды интеллектуального анализа, присущие OLAP.
Понимание OLAP
Что дает OLAP?
- Развитые инструменты доступа к данным хранилища
- Динамическое интерактивное манипулирование данными (вращения, консолидации или детализации)
- Наглядное визуальное отображение данных
- Быстрота – анализ осуществляется в реальном режиме времени
- Многомерное представление данных - одновременный анализ ряда показателей по нескольким измерениям
Для получения эффекта от использования OLAP-технологий необходимо: 1) понимать сущность самих технологий и их возможности; 2) четко определиться, какие процессы необходимо анализировать, какими показателями они будут характеризоваться и в каких измерениях их целесообразно видеть, т. е. создать модель анализа.
Базовые понятия, которыми оперируют OLAP-технологии, следующие:
Многомерность
Для понимания многомерности данных, сначала следует представить таблицу, отображающую, например, выполнение Затрат предприятия по экономическим элементам и бизнес-единицам.
Эти данные представлены в двух измерениях:
- статья
- бизнес-единица
Эта таблица не информативная, так как показывает продажи за один какой-то один промежуток времени. Для различных временных периодов, аналитикам придется сопоставлять несколько таблиц (за каждый временной период):

На рисунке видно 3-е измерение, Время, в дополнение к первым двум. (Статья, бизнес-единица)
Другой способ показать многомерные данные – это представить их в форме куба:



OLAP-кубы позволяют аналитикам получать данные на различных срезах для получения ответов на вопросы, которые ставит бизнес:
- Какие затраты в каких бизнес-единицах критичны?
- Как изменяются затраты бизнес-единиц во времени?
- Как изменяются статьи затрат во времени?
Ответы на подобные вопросы необходимы для принятия управленческих решений: о сокращении определенных статей затрат, влиянии на их структуру, выявление причин изменений затрат во времени, отклонений от плана и их ликвидация – оптимизация их структуры.
В этом примере рассмотрены только 3 измерения. Трудно изобразить более 3-х измерений, но это работает таким же образом, как и в случае с 3-мя измерениями.
Обычно OLAP-приложения позволяют получать данные по 3 и более измерениям, например, можно добавить еще одно измерение – План-Факт, Категория затрат: прямые, косвенные, по Заказам, по Месяцам. Дополнительные измерения позволяют получать больше аналитических срезов и обеспечивают ответы на вопросы с несколькими условиями.
Иерархичность
OLAP также позволяет аналитикам организовывать каждое измерение в виде иерархии, состоящей из групп и подгрупп и итоговых значений, отражающих показатель по всей организации – наиболее логичный способ анализировать бизнес.
Например, затраты целесообразно сгруппировать иерархично:
OLAP позволяет аналитикам получить данные общему сводному показателю (на самом верхнем уровне), а затем детализировать до нижнего и последующего за ним уровня, и таким образом, открыть точную причину изменения показателя.
Позволяя аналитикам использовать несколько измерений в кубе данных, с возможность иерархически построенных измерений, OLAP позволяет получить картину бизнеса, которая не сжата структурой информационного хранилища.
Изменение направлений анализа в кубе (вращение данных)
Как правило, оперируют понятиями: измерения, заданные в столбцах, строках (их может быть несколько), остальные формируют срезы, содержание таблицы формируют размерности (продажи, затраты, денежные средства)
Как правило, OLAP позволяют изменять ориентацию измерений куба, тем самым, представляя данные в различных представлениях.
Отображение данных куба зависит от:
- ориентации измерений: какие измерения заданы в строках, столбцах, срезах;
- групп показателей, выделенных в строках, столбцах, срезах.
- Изменение измерений лежит в области действий пользователя.

Таким образом, OLAP позволяет проводить различные виды анализа и понимать их взаимосвязи их результатов.
- Анализ отклонений – анализ выполнения плана, который дополняется факторным анализом причин отклонений путем детализации показателей.
- Анализ зависимостей: OLAP позволяет выявлять различные зависимости между различными изменениями, например, при удалении из ассортимента пива в течение первых двух месяцев обнаружилось падение продаж воблы.
- Сопоставление (сравнительный анализ). Сравнение результатов изменения показателя во времени, для заданной группы товаров, в различных регионах и др.
- Анализ динамики позволяет выявить определенные тенденции изменения показателей во времени.
Оперативность : можно сказать, что в основу OLAP положены законы психологии: возможность обработки информационных запросов в «реальном времени» - в темпе процесса аналитического осмысления данных пользователем.
Если из реляционной базы данных можно считать около 200 записей в секунду и записать 20, то хороший OLAP-сервер, используя расчетные строки и столбцы, может консолидировать 20 000-30 000 ячеек (эквивалентно одной записи в реляционной базе данных) в секунду.
Наглядность : Следует подчеркнуть, что OLAP предоставляет развитые средства графического представления данных конечному пользователю. Человеческий мозг способен воспринимать и анализировать информацию, которая представлена в виде геометрических образов, в объеме на несколько порядков большем, чем информацию, представленную в алфавитно-цифровом виде. Пример : Пусть Вам требуется найти знакомое лицо на одной из ста фотографий. Я полагаю, что этот процесс займет у Вас не более минуты. А теперь представьте себе, что вместо фотографий Вам предложат сто словесных описаний тех же лиц. Думаю, что Вам вообще не удастся решить предложенную задачу.
Простота : Главной особенностью этих технологий является то, что они ориентированы на использование не специалистом в области информационных технологий, не экспертом-статистиком, а профессионалом в прикладной области - менеджером кредитного отдела, менеджером бюджетного отдела, наконец, директором. Они предназначены для общения аналитика с проблемой, а не с компьютером .
Несмотря на большие возможности OLAP (кроме того, идея сравнительно давняя – 60-е года) реально применение его практически не встречается на наших предприятиях. Почему?
- отсутствует информация или не понятны возможности
- привычка мыслить двумерно
- ценовой барьер
- чрезмерная технологичность статей, посвященных OLAP: отпугивают непривычные термины - OLAP, «раскопка и срезы данных», «нерегламентированные запросы», «выявление существенных корреляций»
Наш подход и западный к применению OLAP
Кроме того, у нас также есть специфическое понимание прикладной полезности OLAP даже при понимании его технологических возможностей.
Наши и российские авторы различных материалов, посвященных OLAP, выражают следующее мнение по отношению к полезности OLAP: большинство воспринимает OLAP как такой инструмент, который позволяет разворачивать и сворачивать данные просто и удобно, осуществляя манипуляции, которые приходят аналитику в голову в процессе анализа. Чем больше «срезов» и «разрезов» данных аналитик видит, тем больше у него идей, которые, в свою очередь, для проверки требуют все новых и новых «срезов». Это неправильно.
В основе западного понимания полезности OLAP лежит методологическая модель анализа, которую необходимо заложить при проектировании OLAP-решений. Аналитик не должен играться с OLAP-кубом и бесцельно изменять его измерения и уровни детализации, ориентацию данных, графическое отображение данных (а это действительно занимает!), а четко понимать, какие представления ему нужны, в какой последовательности и зачем (конечно, элементы «открытий» здесь могут и быть, но это не основополагающий элемент полезности OLAP).
Прикладное использование OLAP
- Бюджет
- Движение денежных средств
Одна из самых благодатных областей применения OLAP-технологий. Не даром ни одна современная система бюджетирования не считается завершенной без наличия в ее составе OLAP-инструментария для анализа бюджета. Большинство бюджетных отчетов легко строятся на основе OLAP-систем. При этом отчеты отвечают на очень широкую гамму вопросов: анализ структуры расходов и доходов, сравнение расходов по определенным статьям у разных подразделений, анализ динамики и тенденций расходов на определенные статьи, анализ себестоимости и прибыли.
OLAP позволит анализировать приходы и оттоки денежных средств в разрезе бизнес-операций, контрагентов, валют и времени с целью их оптимизации потоков.
- Финансовая и управленческая отчетность (с аналитикой, которая необходима руководству)
- Маркетинг
- Balanced Scorecard
- Анализ прибыльности
При наличии соответствующих данных можно найти различное приложение OLAP-технологии.
OLAP -продукты
В данном разделе будет идти речь об OLAP как о программном решении.
Общие требования к OLAP-продуктам
Имеется много путей реализации OLAP приложений, то никакая конкретная технология не должна была быть обязательной, или даже рекомендованной. При разных условиях и обстоятельствах один подход может быть предпочтительнее другого. Техника реализации включает много различных патентованных идей, которыми так гордятся поставщики: разновидности архитектуры «клиент-сервер», анализ временных рядов, объектная ориентация, оптимизация хранения данных, параллельные процессы и т. д. Но эти технологии не могут быть частью определения OLAP.
Есть характеристики, которые должны соблюдаться во всех OLAP-продуктах (если это OLAP-продукт), в которых и заключается идеал технологии. Это 5 ключевых определений, которые характеризуют OLAP (так называемый, тест FASMI): Быстрый Анализ Разделяемой Многомерной Информации .
- Быстрый (FAST) - означает, что система должна обеспечивать выдачу большинства ответов пользователям в пределах приблизительно пяти секунд. Даже если система предупредит, что процесс будет длиться существенно дольше, пользователи, могут отвлечься и потерять мысль, при этом качество анализа страдает. Такую скорость не просто достигнуть с большими количествами данных, особенно, если требуются специальные вычисления «на лету». Поставщики прибегают к широкому разнообразию методов, чтобы достигнуть этой цели, включая специализированные формы хранения данных, обширные предварительные вычисления, или же ужесточая аппаратные требования. Однако полностью оптимизированных решений на сегодняшний день нет. На первый взгляд может казаться удивительным, что при получении отчета за минуту, на который не так давно требовались дни, пользователь очень быстро начинает скучать во время ожиданий, и проект оказывается намного менее успешным, чем в случае мгновенного ответа, даже ценой менее детального анализа.
- Разделяемой означает, что система дает возможность выполнять все требования защиты данных и реализовывать распределенный и одновременный доступ к данным для различных уровней пользователей. Система должна быть способна обработать множественные изменения данных своевременным, безопасным способом. Это - главная слабость многих OLAP продуктов, которые имеют тенденцию предполагать, что во всех приложениях OLAP требуется только чтение, и предоставляют упрощенные средства защиты.
- Многомерной - ключевое требование. Если бы необходимо было определить OLAP одним словом, то выбрали бы его. Система должна обеспечить многомерное концептуальное представление данных, включая полную поддержку для иерархий и множественных иерархий, поскольку это определяет наиболее логичный способ анализировать бизнес. Минимальное число измерений, которые должны быть обработаны, не устанавливается, поскольку это также зависит от приложения, и большинство продуктов OLAP, имеет достаточное количество измерений для тех рынков, на которые они нацелены. И опять же, мы не определяем, какая основная технология базы данных должна использоваться, если пользователь получает действительно многомерное концептуальное представление информации. Эта особенность - сердцевина OLAP
- Информации. Необходимая информация должна быть получена там, где она необходима, независимо от ее объема и места хранения. Однако многое зависит от приложения. Мощность различных продуктов измеряется в терминах того, сколько входных данных они могут обрабатывать, но не сколько гигабайт они могут хранить. Мощность продуктов весьма различна - самые большие OLAP продукты могут оперировать, по крайней мере, в тысячу раз большим количеством данных по сравнению с самыми маленькими. По этому поводу следует учитывать много факторов, включая дублирование данных, требуемую оперативную память, использование дискового пространства, эксплуатационные показатели, интеграцию с информационными хранилищами и т. п.
- Анализ означает, что система может справляться с любым логическим и статистическим анализом, характерным для данного приложения, и обеспечивает его сохранение в виде, доступном для конечного пользователя. Пользователь должен иметь возможность задавать новые специальные вычисления как часть анализа без необходимости программирования. То есть все требуемые функциональные возможности анализа должны обеспечиваться интуитивным способом для конечных пользователей. Средства анализа могли бы включать определенные процедуры, типа анализа временных рядов, распределения затрат, валютных переводов, поиска целей и др. Такие возможности широко отличаются среди продуктов, в зависимости от целевой ориентации.
Другими словами, эти 5 ключевых определений - это цели, на достижение которых ориентированы OLAP-продукты.
Технологические аспекты OLAP
OLAP система включает в себя определенные компоненты. Существуют различные схемы их работы, которые тот или иной продукт может реализовать.
Компоненты OLAP-систем (из чего состоит OLAP-система?)
Как правило, OLAP-система включает в себя следующие компоненты:
- Источник данных
Источник, из которого берутся данные для анализа (хранилище данных, база данных оперативных учетных систем, набор таблиц, комбинации перечисленного). - OLAP-сервер
Данные из источника переносятся или копируются на OLAP-сервер, где они систематизируются и подготавливаются для более быстрого впоследствии формирования ответов на запросы. - OLAP-клиент
Пользовательский интерфейс к OLAP-серверу, в котором оперирует пользователь
Следует отметить, что не все компоненты обязательны. Существуют настольные OLAP-системы, позволяющие анализировать данные, хранящиеся непосредственно на компьютере пользователя, и не требующие OLAP-сервера.
Однако какой элемент обязателен так это источник данных: наличие данных – это важный вопрос. Если они есть, в любом виде, как Excel-таблица, в базе данных учетной системы, в виде структурированных отчетов филиалов ИТ-специалист сможет интегрировать с OLAP-системой напрямую или с промежуточным преобразованием. Для этого OLAP-системы имеют специальные инструменты. Если этих данных нет, или они имеют недостаточную полноту и качество, OLAP не поможет. То есть OLAP – это только надстройка над данными, а если их нет они становятся бесполезной вещью.
Большинство данных для OLAP-приложений возникают в других системах. Однако, в некоторых приложениях (например, для планирования или бюджетирования), данные могут создаваться прямо в OLAP-приложениях. Когда данные поступают из других приложений, обычно необходимо, чтобы данные хранились в отдельном, дублирующем, форме для OLAP-приложения. Поэтому целесообразно создавать хранилища данных.
Следует отметить, что термин «OLAP» неразрывно связан с термином «хранилище данных» (Data Warehouse). Хранилище данных - это предметно-ориентированное, привязанное ко времени и неизменяемое собрание данных для поддержки процесса принятия управляющих решений. Данные в хранилище попадают из оперативных систем (OLTP-систем), которые предназначены для автоматизации бизнес-процессов, хранилище может пополняться за счет внешних источников, например статистических отчетов.
Несмотря на то, что они содержат заведомо избыточную информацию, которая и так есть в базах или файлах оперативных систем, хранилища данных необходимы потому, что:
- разрозненность данных, хранение их в форматах различных СУБД;
- повышается производительность получения данных
- если на предприятии все данные хранятся на центральном сервере БД (что бывает крайне редко), аналитик наверняка не разберется в их сложных, подчас запутанных структурах
- сложные аналитические запросы к оперативной информации тормозят текущую работу компании, надолго блокируя таблицы и захватывая ресурсы сервера
- возможность осуществить очистку и согласование данных
- анализировать данные оперативных систем напрямую невозможно или очень затруднительно;
Задача хранилища - предоставить «сырье» для анализа в одном месте и в простой, понятной структуре. То есть концепция Хранилищ Данных - это не концепция анализа данных, скорее это концепция подготовки данных для анализа. Она предполагает реализацию единого интегрированного источника данных.
OLAP-продукты: архитектуры
При использовании OLAP-продуктов важны 2 вопроса: как и где хранить и обрабатывать данные. В зависимости от того, как реализуются 2 этих процесса различают архитектуры OLAP. Существует 3 способа хранения данных для OLAP и 3 способа обработки этих данных. Многие производители предлагают несколько вариантов, некоторые пытаются доказать, что их подход – единственный самый благоразумный. Это, конечно, абсурд. Однако совсем немного продуктов могут оперировать в более, чем в одном режиме качественно.
Варианты хранения OLAP-данных
Хранение в данном контексте означает содержание данных в постоянно обновляющемся состоянии.
- Реляционные базы данных: это типичный выбор, если на предприятии учетные данных хранятся в РБД. В большинстве случаев, данные следует хранить в денормализованной структуре (самая приемлемая схема «звезда»). Нормализованная база данных не приемлема по причине очень низкой производительности выполнения запросов при формировании агрегированных величин для OLAP (часто итоговые данные хранятся в агрегированных таблицах).
- Файлы баз данных на клиентском компьютере (киоски или витрины данных): эти данные могут заранее распространяться или создаваться по запросам на клиентских компьютерах.
Многомерные базы данных: предполагают, что данные хранятся в многомерной базе данных на сервере. Она может включать данные, извлеченные и просуммированные из других систем и реляционных баз данных, файлов конечных пользователей и др. В большинстве случаев, многомерные базы данных хранятся на диске, но некоторые продукты позволяют использовать и оперативную память, вычисляя наиболее часто используемые данные «на лету». Очень в малом количестве продуктов, основанных на многомерных базах данных, возможно множественное редактирование данных, многие продукты позволяют одиночное изменение, но множественное чтение данных, в то время как другие ограничиваются только чтением.
Эти три места хранения данных имеют различные возможности по объемам хранения, и они расположены в снижающемся по возможностям порядке. Они также имеют различные характеристики производительности при реализации запросов: реляционные базы данных работают гораздо медленнее, чем последние два варианта.
Варианты обработки OLAP-данных
Существует 3 тех же самых варианта обработки данных:
- Использование SQL: этот вариант, конечно же, используется при хранении данных в РБД. Однако SQLне позволяет осуществлять многомерные вычисления одним запросом, поэтому требуется написание сложных SQL-запросов для того, чтобы достичь не более чем обычную многомерную функциональность. Однако это не останавливает разработчиков от попыток. В большинстве случаев, они выполняют ограниченное количество соответствующих вычислений на SQL, с результатами, которые можно получить и при многомерной обработке данных или с клиентской машины. Возможно также использование оперативной памяти, которая может хранить данные, используя более, чем один запрос: это кардинально улучшило отклик.
- Многомерная обработка на клиенте: клиентский OLAP-продукт производит вычисления самостоятельно, но такая обработка доступна только в том случае, если пользователи имеют относительно мощные ПК.
Многомерная обработка на сервере: это популярное место для осуществления многомерных вычислений в клиент-серверных OLAP-приложениях, используется во многих продуктах. Производительность обычно высокая, потому что большинство вычислений уже выполнено. Однако это требует большого дискового пространства.
Матрица OLAP-архитектур
Соответственно путем сочетаний вариантов хранение/обработка, можно получить матрицу архитектур OLAP-систем. Соответственно теоретически может существовать 9 сочетаний этих способов. Однако, так как 3 из них лишены здравого смысла, то в реальности существует только 6 вариантов хранения и обработки OLAP-данных.
|
Варианты хранения многомерных Варианты |
Реляционная база данных |
Серверная многомерная база данных |
Клиентский компьютер |
|
Cartesis Magnitude |
|||
|
Многомерная серверная обработка |
Crystal Holos (ROLAP mode) IBM DB2 OLAP Server CA EUREKA:Strategy Informix MetaCube Speedware Media/MR Microsoft Analysis Services Oracle Express (ROLAP mode) Pilot Analysis Server Applix iTM1 |
Crystal Holos Comshare Decision Hyperion Essbase Oracle Express Speedware Media/M Microsoft Analysis Services PowerPlay Enterprise Server Pilot Analysis Server Applix iTM1 |
|
|
Многомерная обработка на клиентском компьютере |
Oracle Discoverer Informix MetaCube |
Dimensional Insight Hyperion Enterprise |
Cognos PowerPlay Personal Express iTM1 Perspectives |
Так как именно хранение определяет обработку, то принято группировать по вариантам хранения, то есть:
- ROLAP-продукты в секторах 1, 2, 3
- Настольный OLAP – в секторе 6
MOLAP-продукты – в секторах 4 и 5
HOLAP-продукты (позволяющие как многомерный, так и реляционный вариант хранения данных) – во 2 и 4 (выделены курсивом)
Категории OLAP-продуктов
Существует более 40 OLAP-поставщиков, хотя всех их нельзя считать
конкурентами, потому что они возможности их очень сильно отличаются
и, фактически, работают они в различных рыночных сегментах. Они
могут быть сгруппированы в 4 принципиальные категории, в основе
отличия которых лежат понятия: функциональность сложная –
функциональность простая, производительность – дисковое
пространство. Удобно изобразить категории в форме квадрата, потому
что это четко показывает взаимосвязи между ними. Отличительная
черта каждой из категорий представлена на его стороне, а сходства с
другими – на примыкающих сторонах, следовательно, категории на
противоположных сторонах – принципиально отличны.
|
Особенности |
Преимущества |
Недостатки |
Представители |
|
|
Прикладной OLAP |
Законченные приложения, с богатой функциональностью. Практически все требуют многомерной базы данных, хотя некоторые работают и с реляционной. Многие из этой категории приложений специализированы, например, продажи, производство, банковское дело, бюджетирование, финансовая консолидация, анализ продаж |
Возможность интеграции с различными приложениями Высокий уровень функциональности Высокий уровень гибкости и масштабируемости |
Сложность приложения (необходимость обучения пользователя) Высокая стоимость |
Hyperion Solutions Crystal Decisions Information Builders |
|
В основе продукта лежит нереляционная структура данных, обеспечивающая многомерное хранение, обработку и представление данных. Данные в процессе анализа выбираются исключительно из многомерной структуры. Несмотря на высокий уровень открытости, поставщики склоняют покупателей приобретать их же инструментарий |
Высокая производительность (быстрые вычисления суммарных показателей и различные многомерные преобразования по любому из измерений). Среднее время ответа на нерегламентированный аналитический запрос при использовании многомерной БД обычно на 1-2 порядка меньше, чем в случае РБД Высокий уровень открытости: большое количество продуктов, с которыми возможна интеграция Легко справляются с задачами включения в информационную модель разнообразных встроенных функций, проведения пользователем специализированного анализа и т. п. |
Необходимость большого дискового пространства для хранения данных (из-за избыточности данных, которые хранятся). Это крайне неэффективное использование памяти - за счет денормализации и предварительно выполненной агрегации объем данных в многомерной базе соответствует в 2.5-100 раз меньшему объему исходных детализированных данных. В любом случае, MOLAP не позволяют работать с большими базами данных. Реальный предел - база объемом в 10-25 гигабайт Потенциальная возможность «взрыва» базы данных – неожиданное, резкое, непропорциональное возрастание ее объемов Отсутствие гибкости при необходимости модификации структур данных. Любое изменение в структуре измерений почти всегда требует полной перестройки гиперкуба Для многомерных БД, в настоящее время отсутствуют единые стандарты на интерфейс, языки описания и манипулирования данными |
Hyperion (Essbase) |
|
|
DOLAP (Desktop OLAP) |
Клиентские OLAP-продукты, которые достаточно легко внедрить и которые требуют низких затрат в расчете на одно место Речь идет о такой аналитической обработке, где гиперкубы малы, размерность их небольшая, потребности скромны, и для такой аналитической обработки достаточно персональной машины на рабочем столе Цель производителей этого рынка – автоматизация сотен и тысяч рабочих мест, но пользователи должны производить достаточно простой анализ. Покупателей зачастую ориентируют покупать больше рабочих мест, чем это необходимо |
Хорошая интеграция с базами данных: многомерными, реляционными Возможность совершения комплексных покупок, что снижает стоимость проектов внедрения Простота использования приложений |
Весьма ограниченная функциональность (не сравнимы в этом плане со специализированными продуктами) Весьма ограниченная мощность (малые объемы данных, небольшое количество измерений) |
Cognos (PowerPlay) Business Objects Crystal Decisions |
|
Это самый маленький сектор рынка. Детальные данные остаются там, где они были изначально - в реляционной БД; некоторые агрегаты хранятся в той же БД в специально созданных служебных таблицах |
Способны работать с очень большими объемами данных (экономичное хранение) Предусматривают многопользовательский режим работы, в том числе и в режиме редактирования, а не только чтения Более высокий уровень защиты данных и хорошие возможности разграничения прав доступа Возможно частое внесение изменений в структуру измерений (не требуют физической реорганизации БД) |
Низкая производительность, значительно проигрывают по скорости отклика многомерным (отклик на сложные запросы измеряется в минутах или даже часах, чем в секундах). Это более удобные построители отчетов, чем интерактивные аналитические инструменты Сложность продуктов. Требуют значительных затрат на обслуживание специалистами по информационным технологиям. Для обеспечения производительности, сравнимой с MOLAP, реляционные системы требуют тщательной проработки схемы базы данных и настройки индексов, то есть больших усилий со стороны администраторов БД Дорогостоящие для внедрения Ограничения SQL остаются реальностью, что не позволяет реализовать в РСУБД многие встроенные функции, легко обеспечиваемых в системах основанных на многомерном представлении данных |
Information Advantage Informix (MetaCube) |
Следует отметить, что потребители гибридных продуктов, которые позволяют выбирать режим ROLAPи MOLAP, таких как Microsoft Analysis Services, OracleExpress, Crystal Holos, IBM DB2 OLAPServer, почти всегда выбирают режим MOLAP.
Каждая из представленных категорий имеет свои сильные и слабые стороны, нет единственно оптимального выбора. Выбор влияет на 3 важных аспекта: 1) производительность; 2) дисковое пространство для хранения данных; 3) возможности, функциональность и особенно на масштабируемость OLAP-решения. При этом необходимо учитывать объемы обрабатываемых данных, мощность техники, потребности пользователей и искать компромисс между быстродействием и избыточностью дискового пространства, занятого базой данных, простой и многофункциональностью.
Классификация Хранилищ Данных в соответствии с объёмом целевой БД
Недостатки OLAP
Как и любая технология OLAP также имеет свои недостатки: высокие требования к аппаратному обеспечению, подготовке и знаниям административного персонала и конечных пользователей, высокие затраты на реализацию проекта внедрения (как денежные, так и временные, интеллектуальные).
Выбор OLAP-продукта
Правильно выбрать OLAP-продукт сложно, но очень важно, если вы хотите, чтобы проект не провалился.
Как видно, различия продуктов лежат во многих областях: функциональных, архитектурных, технических. Некоторые продукты весьма ограничены в настройках. Некоторые созданы для специализированных предметных областей: маркетинг, продажи, финансы. Есть продукты для общих целей, в которых не заложено прикладное использование, которые должны быть достаточно гибкими. Как правило, такие продукты дешевле, чем специализированные, но здесь больше затраты на внедрение. Спектр OLAP-продуктов очень широк - от простейших средств построения сводных таблиц и диаграмм, входящих в состав офисных продуктов, до средств анализа данных и поиска закономерностей, стоимость которых составляет десятки тысяч долларов.
Как и в любой другой области, в сфере OLAP не может существовать однозначных рекомендаций по выбору инструментальных средств. Можно только заострить внимание на ряде ключевых моментов и сопоставить предлагаемые возможности программного обеспечения с потребностями организации. Важно одно: не обдумав как следует то, как вы собираетесь применять OLAP-инструменты, вы рискуете нажить себе мощную «головную боль».
В процессе выбора необходимо рассмотреть 2 вопроса:
- оценить потребности и возможности предприятия
- оценить существующее на рынке предложение, важны также и тенденции развития
Затем все это сопоставить и, собственно говоря, произвести выбор.
Оценка потребностей
Нельзя сделать рациональный выбор продукта без понимания того, для чего он будет использоваться. Многие компании хотят получить «самое лучшее изделие» без четкого понимания, как оно должно использоваться.
Для того чтобы проект был успешно реализован, финансовый директор должен как минимум грамотно сформулировать перед руководителем и специалистами службы автоматизации свои пожелания и требования. Множество проблем возникает из-за недостаточной подготовленности и информированности для выбора OLAP, специалисты по ИТ и конечные пользователи испытывают трудности общения уже только потому, что манипулируют при разговоре разными понятиями и терминами и выдвигают противоречивые предпочтения. Нужна согласованность в целя в рамках компании.
Некоторые факторы уже стали очевидными после ознакомления с обзором категорий OLAP-продуктов, а именно:
Технические аспекты
- Источники данных: корпоративное хранилище данных, OLTP-система, табличные файлы, реляционные базы данных. Возможность увязки OLAP-инструментария со всеми СУБД, используемыми в организации. Как показывает практика, интеграция разнородных продуктов в устойчиво работающую систему - один из наиболее важных вопросов, и его решение в ряде случаев может быть связано с большими проблемами. Необходимо разобраться, насколько просто и надёжно можно интегрировать средства OLAP с существующими в организации СУБД. Важно также оценить возможности интеграции не только с источниками данных, но и с другими приложениями, в которые, возможно, понадобится экспортировать данные: электронная почта, офисные приложения
- Изменчивость данных, которые учитываются
- Платформа сервера: NT, Unix, AS/400, Linux - но не следует настаивать, чтобы заданные спецификацией OLAP продукты выполнялись на сомнительных или умирающих платформах, которые Вы все еще используете
- Стандарты клиентской части и браузера
- Разворачиваемая архитектура: локальная сеть и модемная связь PC, высокоскоростной клиент/сервер, intranet, extranet, Internet
- Международные особенности: многовалютная поддержка, многоязычные операции, коллективное использование данных, локализация, лицензирование, обновление Windows
Объемы входной информации, которые имеются и которые появятся в будущем
Пользователи
- Сферу приложения: анализ продаж/маркетинга, составление бюджета/планирование, анализ показателей деятельности, анализ бухгалтерских отчетов, качественный анализ, финансовое состояние, формирование аналитических материалов (отчетов)
- Число пользователей и их размещение, требования к разделению прав доступа к данным и функциям, секретность (конфиденциальность) информации
- Вид пользователя: высшее руководство, финансы, маркетинг, HR, продажи, производство и т.д
- Опыт пользователя. Уровень квалификации пользователя. Рассмотреть вопрос о проведении обучения. Очень важно, чтобы клиентское OLAP-приложение было таким, чтобы пользователи чувствовали себя уверенно и могли эффективно его использовать.
Ключевые особенности: потребность в обратной записи данных, распределенные вычисления, сложные валютные преобразования, потребности в печати отчетов, интерфейс электронной таблицы, сложность логики приложения, необходимая размерность, типы анализа: статистический, поиск цели, анализ «что если»
Внедрение
- Кто будет заниматься внедрением и эксплуатацией: внешние консультанты, внутренняя служба ИТ или конечные пользователи
- Бюджет: программное обеспечение, аппаратные средства, услуги, передача данных. Помните, что оплата лицензий OLAP-продукта это только маленькая часть общей стоимости проекта. Внедрение и аппаратные затраты могут быть больше, чем плата за лицензию, а длительная поддержка, эксплуатация и затраты администрации почти наверное значительно больше. И если Вы приняли неправильное решение покупки неподходящего продукта только потому, что оно более дешевое, окончательно Вы можете иметь более высокую общую стоимость проекта из-за более высоких расходов на обслуживание, администрацию и(или) аппаратных затрат при том, что вероятно, Вы получите более низкий уровень деловых выгод. При прикидке общих затрат не забудьте выяснить следующие вопросы: Насколько широк выбор источников для внедрения, обучения, и поддержки? Является ли потенциальный общий фонд (служащих, подрядчиков, консультантов) склонным к росту или сокращению? Насколько широко может быть использован свой производственный профессиональный опыт?
Несмотря на то, что стоимость аналитических систем даже сегодня остается достаточно высокой, а методологии и технологии реализации таких систем находятся ещё в стадии их становления, уже сегодня, экономический эффект обеспечиваемый ими существенно превышает эффект от традиционных оперативных систем.
Эффект от правильной организации, стратегического и оперативного планирования развития бизнеса трудно заранее оценить в цифрах, но очевидно, что он в десятки и даже сотни раз может превзойти затраты на реализацию таких систем. Однако не следует и заблуждаться. Эффект обеспечивает не сама система, а люди с ней работающие. Поэтому не совсем корректны декларации типа: «система Хранилищ Данных и OLAP-технологий будет помогать менеджеру принимать правильные решения». Современные аналитические системы не являются системами искусственного интеллекта и они не могут ни помочь, ни помешать в принятии решения. Их цель своевременно обеспечить менеджера всей информацией необходимой для принятия решения в удобном виде. А какая информация будет запрошена и какое решение будет принято на её основе, зависит только от конкретного человека ее использующего.
Остается сказать только одно, эти системы могут помочь разрешить многие бизнес-проблемы и могут иметь далеко идущий положительный эффект. Остается только ждать, кто первым осознает преимущества этого подхода и окажется впереди других.
OLAP (от англ. OnLine Analytical Processing - оперативная аналитическая обработка данных, также: аналитическая обработка данных в реальном времени, интерактивная аналитическая обработка данных) - подход к аналитической обработке данных, базирующийся на их многомерном иерархическом представлении, являющийся частью более широкой области информационных технологий - бизнес-аналитики ().
Каталог OLAP-решений и проектов смотрите в разделе OLAP на TAdviser.
С точки зрения пользователя, OLAP -системы представляют средства гибкого просмотра информации в различных срезах, автоматического получения агрегированных данных, выполнения аналитических операций свёртки, детализации, сравнения во времени. Всё это делает OLAP-системы решением с очевидными преимуществами в области подготовки данных для всех видов бизнес-отчетности, предполагающих представление данных в различных разрезах и разных уровнях иерархии - например, отчетов по продажам, различных форм бюджетов и так далее. Очевидны плюсы подобного представления и в других формах анализа данных, в том числе для прогнозирования.
Требования к OLAP-системам. FASMI
Ключевое требование, предъявляемое к OLAP-системам - скорость, позволяющая использовать их в процессе интерактивной работы аналитика с информацией. В этом смысле OLAP-системы противопоставляются, во-первых, традиционным РСУБД , выборки из которых с типовыми для аналитиков запросами, использующими группировку и агрегирование данных, обычно затратны по времени ожидания и загрузке РСУБД , поэтому интерактивная работа с ними при сколько-нибудь значительных объемах данных сложна. Во-вторых, OLAP-системы противопоставляются и обычному плоскофайловому представлению данных, например, в виде часто используемых традиционных электронных таблиц, представление многомерных данных в которых сложно и не интуитивно, а операции по смене среза - точки зрения на данные - также требуют временных затрат и усложняют интерактивную работу с данными.
При этом, с одной стороны, специфичные для OLAP-систем требования к данным обычно подразумевают хранение данных в специальных оптимизированных под типовые задачи OLAP структурах, с другой сторны, непосредственное извлечение данных из существующих систем в процессе анализа привело бы к существенному падению их производительности.
Следовательно, важным требованием является обеспечение макимально гибкой связки импорта-экспорта между существующими системами, выступающими в качестве источника данных и OLAP-системой, а также OLAP-системой и внешними приложениями анализа данных и отчетности.
При этом такая связка должна удовлетворять очевидным требованиям поддержки импорта-экспорта из нескольких источников данных, осуществления процедур очистки и трансформации данных, унификации используемых классификаторов и справочников. Кроме того, к этим требованиям добавляется необходимость учёта различных циклов обновления данных в существующих информационных системах и унификации требуемого уровня детализации данных. Сложность и многогранность этой проблемы привела к появлению концепции хранилищ данных , и, в узком смысле, к выделению отдельного класса утилит конвертации и преобразования данных - ETL (Extract Transform Load) .
Модели хранения активных данных
Выше мы указали, что OLAP предполагает многомерное иерархическое представление данных, и, в каком-то смысле, противопоставляется базирующимся на РСУБД системам.
Это, однако, не значит, что все OLAP-системы используют многомерную модель для хранения активных, "рабочих" данных системы. Так как модель хранения активных данных оказывает влияние на все диктуемые FASMI-тестом требования, её важность подчёркивается тем, что именно по этому признаку традиционно выделяют подтипы OLAP - многомерный (MOLAP), реляционный (ROLAP) и гибридный (HOLAP).
Вместе с тем, некоторые эксперты, во главе с вышеупомянутым Найджелом Пендсом , указывают, что классификация, базирующаяся на одном критерии недостаточно полна. Тем более, что подавляющее большинство существующих OLAP-систем будут относиться к гибридному типу. Поэтому мы более подробно остановимся именно на моделях хранения активных данных, упомянув, какие из них соответствуют каким из традиционных подтипов OLAP.
Хранение активных данных в многомерной БД
В этом случае данные OLAP хранятся в многомерных СУБД , использующих оптимизированные для такого типа данных конструкции. Обычно многомерные СУБД поддерживают и все типовые для OLAP операции, включая агрегацию по требуемым уровням иерархии и так далее.
Этот тип хранения данных в каком-то смысле можно назвать классическим для OLAP. Для него, впрочем, в полной мере необходимы все шаги по предварительной подготовке данных. Обычно данные многомерной СУБД хранятся на диске, однако, в некоторых случаях, для ускорения обработки данных такие системы позволяют хранить данные в оперативной памяти . Для тех же целей иногда применяется и хранение в БД заранее рассчитанных агрегатных значений и прочих расчётных величин.
Многомерные СУБД , полностью поддерживающие многопользовательский доступ с конкурирующими транзакциями чтения и записи достаточно редки, обычным режимом для таких СУБД является однопользовательский с доступом на запись при многопользовательском на чтение, либо многопользовательский только на чтение.
Среди условных недостатков, характерных для некоторых реализаций многомерных СУБД и базирующихся на них OLAP-систем можно отметить их подверженность непредсказуемому с пользовательской точки зрения росту объёмов занимаемого БД места. Этот эффект вызван желанием максимально уменьшить время реакции системы, диктующим хранить заранее рассчитанные значения агрегатных показателей и иных величин в БД, что вызывает нелинейный рост объёма хранящейся в БД информации с добавлением в неё новых значений данных или измерений.
Степень проявления этой проблемы, а также связанных с ней проблем эффективного хранения разреженных кубов данных, определяется качеством применяемых подходов и алгоритмов конкретных реализаций OLAP-систем.
Хранение активных данных в реляционной БД
Могут храниться данные OLAP и в традиционной РСУБД . В большинстве случаев этот подход используется при попытке «безболезненной» интеграции OLAP с существующими учётными системами, либо базирующимися на РСУБД хранилищами данных . Вместе с тем, этот подход требует от РСУБД для обеспечения эффективного выполнения требований FASMI-теста (в частности, обеспечения минимального времени реакции системы) некоторых дополнительных возможностей. Обычно данные OLAP хранятся в денормализованном виде, а часть заранее рассчитанных агрегатов и значений хранится в специальных таблицах. При хранении же в нормализованном виде эффективность РСУБД в качестве метода хранения активных данных снижается.
Проблема выбора эффективных подходов и алгоритмов хранения предрассчитанных данных также актуальна для OLAP-систем, базирующихся на РСУБД, поэтому производители таких систем обычно акцентируют внимание на достоинствах применяемых подходов.
В целом считается, что базирующиеся на РСУБД OLAP-системы медленнее систем, базирующихся на многомерных СУБД, в том числе за счет менее эффективных для задач OLAP структур хранения данных, однако на практике это зависит от особенностей конкретной системы.
Среди достоинств хранения данных в РСУБД обычно называют большую масштабируемость таких систем.
Хранение активных данных в «плоских» файлах
Этот подход предполагает хранение порций данных в обычных файлах. Обычно он используется как дополнение к одному из двух основных подходов с целью ускорения работы за счет кэширования актуальных данных на диске или в оперативной памяти клиентского ПК.
Гибридный подход к хранению данных
Большинство производителей OLAP-систем, продвигающих свои комплексные решения, часто включающие помимо собственно OLAP-системы СУБД , инструменты ETL (Extract Transform Load) и отчетности, в настоящее время используют гибридный подход к организации хранения активных данных системы, распределяя их тем или иным образом между РСУБД и специализированным хранилищем, а также между дисковыми структурами и кэшированием в оперативной памяти.
Так как эффективность такого решения зависит от конкретных подходов и алгоритмов, применяемых производителем для определения того, какие данные и где хранить , то поспешно делать выводы о изначально большей эффективности таких решений как класса без оценки конкретных особенностей рассматриваемой системы.
OLAP (англ. on-line analytical processing) – совокупность методов динамической обработки многомерных запросов в аналитических базах данных. Такие источники данных обычно имеют довольно большой объем, и в применяемых для их обработки средствах одним из наиболее важных требований является высокая скорость. В реляционных БД информация хранится в отдельных таблицах, которые хорошо нормализованы. Но сложные многотабличные запросы в них выполняются довольно медленно. Значительно лучшие показатели по скорости обработки в OLAP-системах достигаются за счет особенности структуры хранения данных. Вся информация четко организована, и применяются два типа хранилищ данных: измерения (содержат справочники, разделенные по категориям, например, точки продаж, клиенты, сотрудники, услуги и т.д.) и факты (характеризуют взаимодействие элементов различных измерений, например, 3 марта 2010 г. продавец A оказал услугу клиенту Б в магазине В на сумму Г денежных единиц). Для вычисления результатов в аналитическом кубе применяются меры. Меры представляют собой совокупности фактов, агрегированных по соответствующим выбранным измерениям и их элементам. Благодаря этим особенностям на сложные запросы с многомерными данными затрачивается гораздо меньшее время, чем в реляционных источниках.
Одним из основных вендоров OLAP-систем является корпорация Microsoft . Рассмотрим реализацию принципов OLAP на практических примерах создания аналитического куба в приложениях Microsoft SQL Server Business Intelligence Development Studio (BIDS) и Microsoft Office PerformancePoint Server Planning Business Modeler (PPS) и ознакомимся с возможностями визуального представления многомерных данных в виде графиков, диаграмм и таблиц.
Например, в BIDS необходимо создать OLAP-куб по данным о страховой компании, ее работниках, партнерах (клиентах) и точках продаж. Допустим предположение, что компания предоставляет один вид услуг, поэтому измерение услуг не понадобится.
Сначала определим измерения. С деятельности компании связаны следующие сущности (категории данных):
- Точки продаж
- Сотрудники
- Партнеры
Далее необходима одна таблица для хранения фактов (таблица фактов).
Информация в таблицы может вноситься вручную, но наиболее распространена загрузка данных с применением мастера импорта из различных источников.
На следующем рисунке представлена последовательность процесса создания и заполнения таблиц измерений и фактов вручную:
Рис.1. Таблицы измерений и фактов в аналитической БД. Последовательность создания
После создания многомерного источника данных в BIDS имеется возможность просмотреть его представление (Data Source View). В нашем примере получится схема, представленная на рисунке ниже.
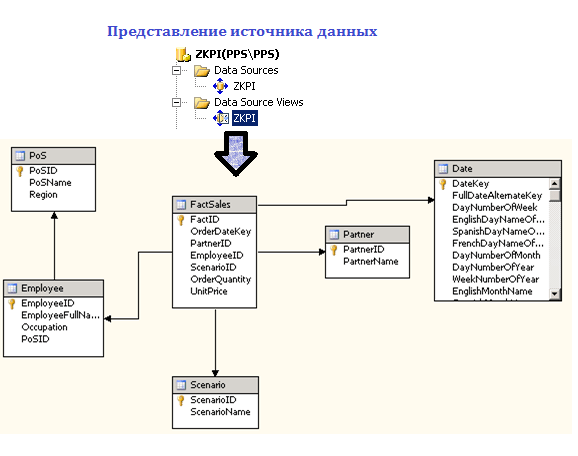
Рис.2. Представление источника данных (Data Source View) в Business Intellingence Development Studio (BIDS)
Как видим, таблица фактов связана с таблицами измерений посредством однозначного соответствия полей-идентификаторов (PartnerID, EmployeeID и т.д.).
Посмотрим на результат. На вкладке обозревателя куба, перетаскивая меры и измерения в поля итогов, строк, столбцов и фильтров, можем получить представление интересующих данных (к примеру, заключенные сделки по страховым договорам, заключенные определенным работником в 2005 году).









